FredBet – Ein Tippspiel auf dem Weg in die Cloud
Nur noch wenige Tage und die Fußball-Europameisterschaft öffnet ihre Tore in Frankreich. Wenn auch nur alle zwei bzw. vier Jahre (EM bzw. WM), so ist das gemeinsame Wetteifern unter Freunden und Kollegen ein großer Spaß. Mit Bier und Grillwurst bewaffnet fiebert man dem Weiterkommen der deutschen Mannschaft bis zum Schlusspfiff entgegen. Um dem Wetteifern noch mehr Nachdruck zu verleihen fehlt es nur noch an einem kleinen Tippspiel, bei dem man seine Kenntnisse über die vermeintlich bessere Mannschaft unter Beweis stellen kann.
Von der Idee zur Anwendung
Die Idee wäre also geboren. Doch welche Technologie wählt man für eine kleine Anwendung, die man mal so “nebenbei” entwickeln kann und bis spätestens zum Eröffnungsspiel produktiv sein sollte? Nach ein paar Überlegungen sollten diese nicht-funktionalen Anforderungen erfüllt sein:
- Die Entwicklungsumgebung sollte möglichst einfach aufzusetzen sein.
- Die Anwendung sollte auch über das Smartphone bedienbar sein. So kann ein (fast) vergessener Tipp noch kurz vor dem Anpfiff vor dem Fernseher abgegeben werden.
- Die Zeit für Build, Deployment und Betrieb der Anwendung sollte möglichst kurz und komfortabel sein. Aus Entwicklersicht möchte man seine knappe Zeit für die wirklich wichtigen Features investieren und nicht mit der Einrichtung von Servern.
Nach reichlicher Überlegung wurde folgender Technologie-Stack gewählt:
- Spring Boot mit Thymeleaf als Templating-Engine
- Spring Security für Authentifizierung und Autorisierung
- Responsive Design mit Bootstrap
- MariaDB als Datenbank
- automatischer Build und Deployment der Anwendung über eine Continuous Delivery Pipeline im Thoughtworks GO-Server
- Betrieb als Docker-Container über die Docker Cloud mit Hosting über Amazon Web Services (AWS)
- Monitoring der Anwendung über Graylog 2
Das Aufsetzen einer neuen Anwendung mit Spring Boot ist recht einfach. Über die Spring Initializr Website kann man sich das Grundgerüst als Maven oder Gradle Projekt direkt generieren lassen. Spring Boot bringt gleich den benötigten Web-Servlet-Container (Tomcat oder Jetty) mit und erzeugt eine komplette JAR-Datei (sog. Fat-Jar), die alle Abhängigkeiten inkl. dem Servlet-Container beinhaltet. So muss kein separater Tomcat für Entwicklung und Betrieb installiert werden. Durch die Bündelung der Anwendung mit der Laufzeitumgebung eignet sich Spring Boot besonders für Microservice-Architekturen. In unserem Fall macht eine weitere Unterteilung nach fachlichen Gesichtspunkten aufgrund der geringen Anwendungsgröße allerdings keinen Sinn. Aus Architektursicht entspricht die (autonome) Anwendung daher eher einem Self-Contained System.
Die Entwicklungsumgebung ist schnell eingerichtet, da jede Spring Boot Anwendung über eine Start-Klasse mit main-Methode verfügt, über die sich die Anwendung inkl. Tomcat starten lässt. Über Spring Data JPA lässt sich die Integration mit der Datenbank schnell erledigen. Auf Basis einer Methodennamen-Konvention kann hier weitgehend auf die Implementierung eigener Abfragen verzichtet werden.
Als Web-Framework im Hinblick auf die Verwendung mit mobilen Clients hätte sich AngularJS angeboten. Da meine derzeitige Kenntnis darüber aber so knapp wie die verbleibende Zeit bis zum Eröffnungsspiel ist, habe ich mich für die Kombination aus Spring MVC und Thymeleaf entschieden. Thymeleaf als Template-Engine hat eine gute Integration in das Spring-Framework und ermöglicht den Verzicht auf die klassischen JSP-Seiten. Die HTML5-Templates werden über einen eigenen Namespace und die Spring Expression Language mit den dynamischen Anteilen gefüllt. Die Templates sind auch statisch im Browser aufrufbar, wobei die ggf. enthaltenen Texte nicht einmal entfernt werden müssen. Das macht ein statisches Prototyping des Layouts extrem komfortabel. Die Verwendung von Bootstrap ermöglicht ein responsives Design, so dass alle Seiten auch auf einem mobilen Endgerät benutzbar bleiben.
Nach ein paar fleißigen Stunden kann sich unser Tippspiel schon sehen lassen:
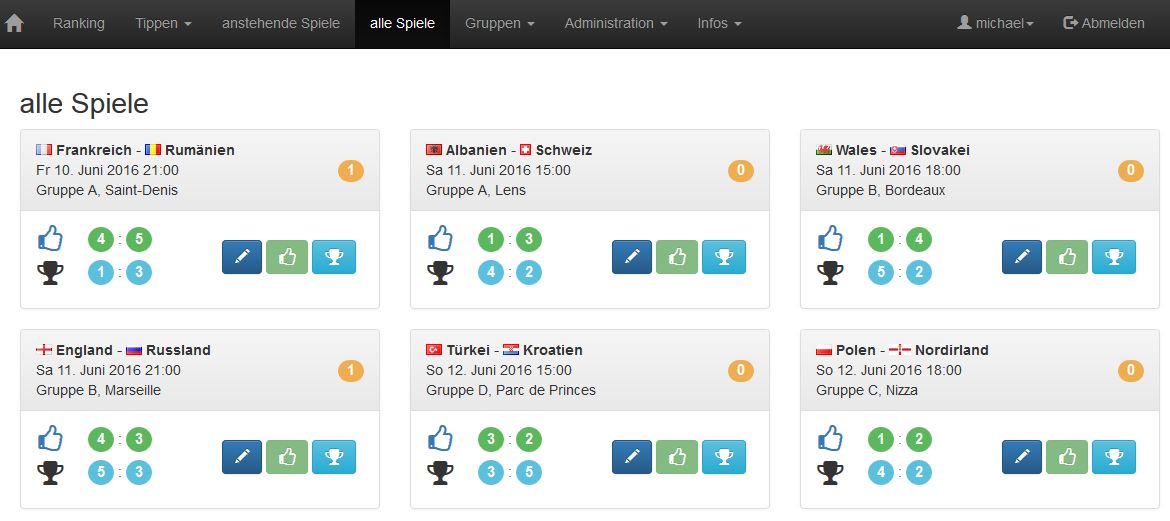
Einrichtung einer Deployment Pipeline
Nachdem das Tippspiel einen vorzeigbaren Stand erreicht hat, soll es auch Freunden und Kollegen möglich sein die Anwendung zu testen bzw. später auch zu nutzen. Da diese Situation nach jeder Änderung wieder eintreten wird, soll dieser Prozess möglichst einfach wiederholbar sein. Das Zauberwort heißt “Continuous Delivery” und führt letztendlich zu einer Automatisierung der einzelnen Schritte vom Build bis zum Deployment der Anwendung in Produktion.
Die Entscheidung für diese Aufgabe fiel auf den Continuous Delivery Server Go von Thoughtworks. Die Automatisierungsschritte werden dafür in einer sog. Deployment Pipeline zusammengefasst.
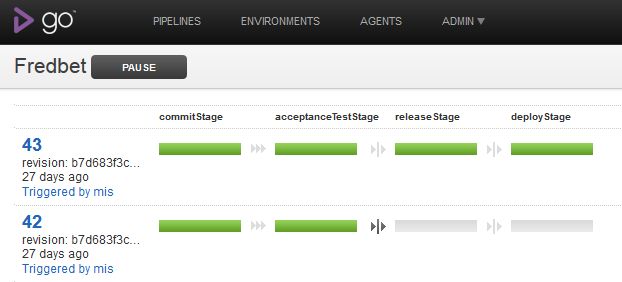
In der Commit-Stage werden die Sourcen kompiliert und die Unit- und Integrationstests ausgeführt. Anschließend werden in der Acceptance-Test-Stage die Akzeptanztests ausgeführt. Weitere Stages, z.B. für Performance- und Lasttests, könnten optional hinzugefügt werden. In der Release-Stage wird dann die Anwendung unter einer einheitlichen Versionsnummer in der Versionsverwaltung getaggt und in einen Docker-Container verpackt. Der Docker-Container wird anschließend auf Docker Hub hochgeladen. In der letzten Stage (Deploy-Stage) wird die Anwendung in der Docker-Cloud auf Basis des hochgeladenen Containers neu deployt. Das Deployment kann mit Hilfe der Docker-Cloud-CLI recht einfach automatisiert werden:
docker-cloud service redeploy SERVICENAME.STACKNAME.USER_ID.svc.dockerapp.io
Die ersten beiden Stages werden automatisch nach einem Commit in die Versionsverwaltung ausgelöst. Die Release- und Deploy-Stages werden manuell getriggert, um den Zeitpunkt eines Releases bzw. eines Deployments selbst festzulegen. Für ein Continuous Deployment könnte man aber auch die manuellen durch automatische Trigger ersetzen. In dem Fall führt dann jeder Commit (bzw. Git-Push) zu einem Deployment der Anwendung.
Wer keinen eigenen CD-Server betreiben möchte, kann auch auf eine gehostete Alternative setzen. Ein Beispiel dafür wäre z.B. CircleCI, dass ebenfalls das Erstellen von Docker-Containern unterstützt.
Betrieb in der Docker Cloud und Amazon Web Services (AWS)
In Zeiten von Continuous Delivery, DevOps und Cloud Computing ist es einfacher den je eine Anwendung zu betreiben. Die Angebote für Platform as a Service (PaaS) Dienstleistungen sind mittlerweile recht umfangreich und vielfältig geworden. Aus Entwicklersicht ist es dabei besonders komfortabel auf eine bestehende Cloud-Infrastruktur zurückgreifen zu können. Die Installation der Anwendung in einem einheitlichen Format in Form eines Docker-Containers inklusive der Laufzeitumgebung macht die Inbetriebnahme noch einfacher und weniger fehleranfällig, als in einem proprietären Format, wie z.B. WAR oder EAR-Dateien.
Das Hosting der Docker-Container wird in der Docker Cloud über sog. Cloud Provider vorgenommen. Die Administration bzw. Orchestrierung der Container erfolgt damit ausschließlich in der Docker Cloud und das Hosting der Container über einen Cloud Provider, wie z.B. Amazon Web Services, DigitalOcean oder Microsoft Azure. Die angemieteten Server werden als Nodes in der Docker Cloud hinzugefügt. Ein Cloud Provider muss allerdings zuvor mit Hilfe eines Access-Keys und entsprechenden Policies in den Einstellungen von AWS freigeschaltet werden.
Die Konfiguration der verwendeten Container wird über ein sog. Stack-File vorgenommen. Die in Yaml-Format gepflegte Datei entspricht dabei weitestgehend der Syntax von Docker Compose.
Hier ein Beispiel für ein Stack-File mit MariaDB und Graylog-Server:
fredbet:
image: 'hamsterhase/fredbet:latest'
environment:
- JDBC_PASSWORD=password
- 'JDBC_URL=jdbc:mariadb://mariadb:3306/fredbetdb'
- JDBC_USERNAME=fred
- spring.profiles.active=docker
links:
- graylog
- mariadb
ports:
- '80:8080'
tags:
- app
graylog:
image: 'graylog2/allinone:latest'
environment:
- GRAYLOG_NODE_ID=my_graylog
- GRAYLOG_PASSWORD=password
- GRAYLOG_SERVER_SECRET=secret
- GRAYLOG_TIMEZONE=Europe/Berlin
ports:
- '9000:9000'
- '12201:12201'
tags:
- graylog
volumes:
- '/graylog/data:/var/opt/graylog/data'
- '/graylog/logs:/var/log/graylog'
mariadb:
image: 'mariadb:10.1.11'
environment:
- MYSQL_DATABASE=fredbetdb
- MYSQL_PASSWORD=password
- MYSQL_ROOT_PASSWORD=secred
- MYSQL_USER=fred
ports:
- '3306:3306'
tags:
- db
volumes:
- /data/dbDie Administration der Datenbank kann ebenfalls vereinfacht werden, wenn man auf eine gehostete Version zurückgreift (z.B. Amazon RDS). Das erleichtert z.B. das Erstellen von automatischen Backups.
Nach dem Start des Container-Stacks werden die einzelnen Container als Services angezeigt:
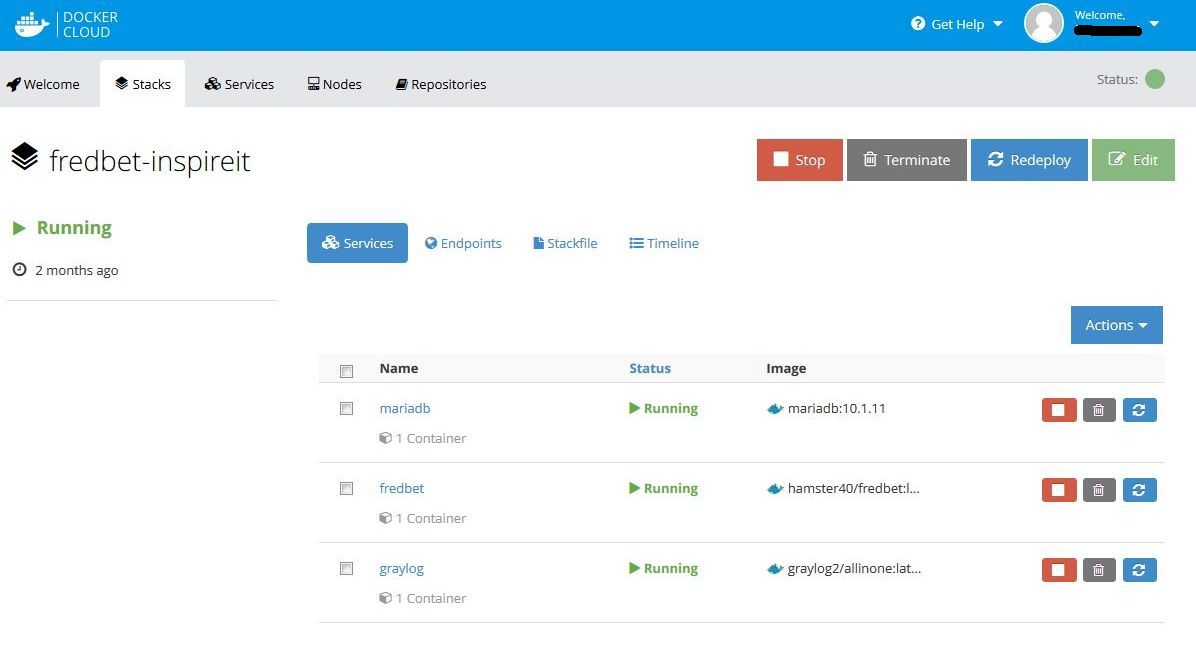
Das Tippspiel ist nun öffentlich erreichbar. Die Endpoint-URL ist allerdings noch etwas kryptisch. Die URL sieht dann in etwa so aus:
http://STACKNAME.SERVICENAME.USER_ID.svc.dockerapp.io
Abhilfe schafft hier die Registrierung einer eigenen Domain. Das geht z.B. über den Amazon Route 53-Service besonders komfortabel. Die Beantragung, Einrichtung und Abrechnung erfolgt dann über das Amazon-Konto. Mit einem DNS-Eintrag kann dann von dem registrierten Domain-Namen auf die Docker-Cloud-URL weitergeleitet werden.
Monitoring mit Graylog 2
In der Docker Cloud steht bereits ein rudimentäres Monitoring bereit. Das beschränkt sich allerdings nur auf den Zugriff der Log-Konsole.
Für den Betrieb eines einzelnen Containers kann das noch ausreichend sein. Allerdings kommt man meist nicht nur mit einem Container aus und man braucht schnell eine übergreifende Lösung, die unterschiedliche Log-Informationen aus unterschiedlichen Quellen unter einer Oberfläche zusammenfasst. Die hier verwendete Open Source Lösung heißt Graylog 2.
Graylog 2 besteht wiederum aus dem Graylog-Server, Elasticsearch für die Indexierung von Log-Meldungen und einer Mongo-Datenbank für die Konfigurationseinstellungen. Die einfachste Lösung ist die Verwendung des fertigen Docker-Containers, den es als “All-In-One” Lösung gibt (siehe Stack-File oben).
Die Konfiguration für das Senden der Log-Informationen an Graylog kann auf zwei unterschiedliche Arten erfolgen: Entweder man verwendet den nativen Log-Driver in Docker (GELF-Driver) oder die Log-Meldungen werden direkt aus der Anwendung z.B. mittels Log4J 2 versendet. Der erste Ansatz hat den Vorteil, dass alle Container-Meldungen an Graylog gesendet werden können (siehe auch Centralized Docker Container Logging With Native Graylog Integration). Mit dem zweiten Ansatz verlagert man die Konfiguration auf die Anwendung und ermöglicht damit ein feingranulares Log-Verhalten.
Das GELF-Format (Graylog Extended Log Format) ist ein einheitliches Log-Format, um Log-Informationen standardisiert durchsuchbar und auswertbar zu machen.
Für unser Tippspiel wurde der zweite Ansatz gewählt. Die Log4J2-Konfiguration ist dabei recht einfach:
<?xml version="1.0" encoding="UTF-8"?>
<configuration status="warn" packages="org.graylog2.log4j2">
<appenders>
<GELF name="gelfAppender" server="graylog" port="12201" protocol="UDP"/>
</appenders>
<loggers>
<logger name="de.fred4jupiter.fredbet" level="DEBUG" />
<root level="INFO">
<appender-ref ref="gelfAppender" />
</root>
</loggers>
</configuration>Über den GELF-Appender werden die Log-Meldungen direkt an den Graylog-Server gesendet. Die sendende Anwendung wird dann in Graylog über einen neuen „Input“-Eintrag bekanntgegeben. Die unterschiedlichen Suchanfragen können letztendlich dann auch zu einem einfachen Dashboard zusammengefasst werden.
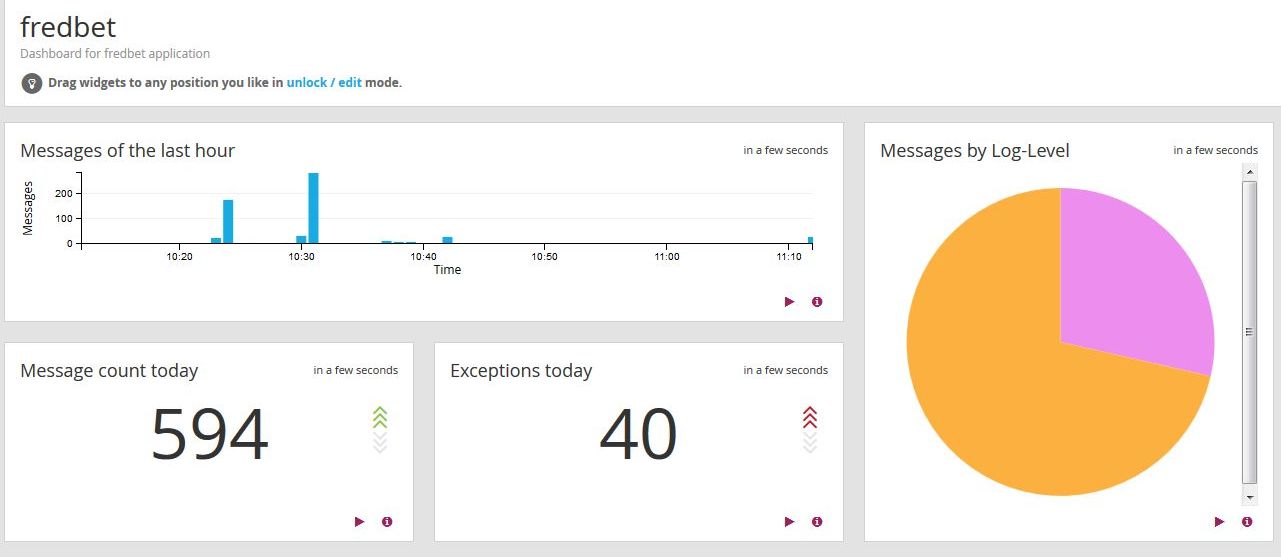
Fazit
Die Entwicklung des Tippspiels mittels Spring Boot, Docker und Docker Cloud hat sich als sehr einfach und komfortabel herausgestellt. Die Deployment-Pipeline übernimmt dabei die lästigen Arbeiten für die Produktivnahme von Änderungen. Die Kosten bleiben dabei noch überschaubar: Der Docker Cloud Account ist für einen Node und eine private Registry kostenlos. Bei einer AWS-Neuregistrierung kann man eine Micro-Instanz ein Jahr lang kostenlos betreiben. Lediglich ein paar Cent für das DNS-Routing und ein paar Euro für die Domain-Registrierung werden fällig.
Einer fröhlichen Fußball-Europameisterschaft mit Tippspiel unter Freunden steht also nichts mehr im Wege. Für ein eigenes Tipp-Erlebnis stehen die Sourcen von FredBet unter GitHub als Open Source zur Verfügung.