Mythos der Trunk-basierten Entwicklung (Vortragstext)
Dieser Blogartikel ist als Begleitmaterial zum gleichnamigen Vortrag auf der Continuous Lifecycle 2016 gedacht.
Wir wollen Sie in diesem Blog daher auf eine Reise mitnehmen und von unseren Erfahrungen mit verschiedenen Code Commit Workflows berichten. Einige Teile des Weges waren in der Tat etwas steinig und manchmal war auch nicht ganz klar wohin der Weg führt.
Mal gab es in der Reisegruppe Leute, die meinten, sie wissen wohin der Weg führt und alle mussten folgen. Bei anderen Abzweigungen haben wir dann erst einmal in Ruhe eine Ortsbestimmung gemacht: wo stehen wir, wo wollen wir hin und wie erreichen wir die Ziele am Besten.
Die Reise haben wir nicht alleine unternommen. Wir waren insgesamt 27 Entwickler und Tester, die mit uns auf der Reise waren und die direkt von den Richtungsentscheidungen betroffen waren.
Rahmenbedingungen
Doch erst einmal zu den Rahmenbedingungen. Das Projekt über das wir hier berichten entwickelt in 2 wöchentlichen Iterationen in einem SAFe basierten Prozess. Beteiligt sind dabei 4 Java Entwicklungsteams, die 6 Fachmodule entwickeln.
Am Anfang der Reise: Story Branches
Die Teams erhalten entsprechend des agilen Prozesses User Stories zur Entwicklung. Die Frage, die am Anfang der Reise stand, war, wie wir mit unfertigen Stories umgehen. Bei dieser Diskussion haben sich diejenigen durchgesetzt, die keine unfertigen Stories ausliefern wollen, auch wenn alle bis dahin entwickelten Tests weiterhin erfolgreich absolviert werden. Als Muster haben wir dafür die Entwicklung in Story Branches gewählt.
Jedes Fachmodul soll später möglichst unabhängig von anderen Modulen in Produktion gebracht werden und auch skaliert werden können. Daher wurde jedes Fachmodul entwickelt und in Jenkins unabhängig von den anderen gebaut. Damit sollten wir möglichst große Freiheit haben und freie Fahrt für jedes Modul existieren.
Die Realität sah aber anders aus. Zum einen gab es eine Menge Geschwindigkeitsbegrenzungen z.B. in Form von gemeinsamen Libraries. Als ein prominentes Beispiel gibt es auch in diesem Projekt das typische “commons” Modul. Gleichzeitig ist es für viele Features notwendig, dass in mehreren Modulen Funktionalität entwickelt wird. Module sind also über ihre Schnittstellen gekoppelt. Für die Fachmodule innerhalb des Projekts wurden daher Clientmodule entwickelt (externe Projekte erhalten nur die REST Schnittstellenbeschreibung). Wir wollen hier nicht die Vor- und Nachteile von common Libraries und Client Modulen diskutieren. Jede Architekturentscheidung beinhaltet Trade-offs. Für uns scheinen die Vorteile zu überwiegen, da die Nutzung nur auf das eine Projekt beschränkt ist. Aus Geschwindigkeitsbegrenzungen wurde aber häufig auch ein Stau. Ein Fachmodul musste eine neue Version “releasen”, d.h. es musste eine neue Version im Nexus Repository deployed sein, bevor diese Version dann in konsumierenden Modulen genutzt werden musste. Es mussten also häufig manuell Versionsnummern aktualisiert werden.
Wir standen also vor der Entscheidung, wie wir weiter machen. An dieser Stelle haben wir eine Standortbestimmung vorgenommen. Wir hätten die Kopplung über die Common Module und Client Libraries abschaffen können, aber wie schon gesagt überwiegen für das Projekt die Vorteile. Allerdings sind wir bei einer Neuentwicklung eines Produkts und nicht bei der Weiterentwicklung. Wir stellen daher fest, dass wir die unabhängigen Releasezyklen gar nicht benötigen. Wir können genau so gut getrennt entwickeln und gemeinsam bauen und deployen. Zu diesem Zeitpunkt ist die Laufzeit der Buildpipeline kein Problem. Was haben daher alle Fachmodule (die jeweils ein Multi-Module Maven Projekt waren) noch einmal unter einem gemeinsamen Oberprojekt zusammen zu fassen. Und diese Multi-Multi-Modul-Projekt dann zusammen zu bauen. Damit haben wir das große Stau verursachende Problem der händischen Versionsnummernaktualisierung gelöst. Gleichzeitig müssen wir in Jenkins nicht mehr 7 Buildprojekte managen, sondern nur noch eins. Wir haben eine Menge Komplexität reduziert, die uns eher behindert als geholfen hat. Gleichzeitig haben wir keine der Architekturvorteile der Modulseparierung aufgegeben. Das haben wir doch gut gemacht, oder? Es gab immer noch ein großes Problem, welches sich immer gegen Ende des Sprints zeigte: Auf die Frage des Product Owners, ob wir eine Story im Review zeigen konnten, gab es häufig die Antwort “Muss nur noch gemerged werden”. Und das hieß leider viel zu oft: “… also nein”, denn ein Story Branch in einem aktiven Projekt entfernt sich sehr schnell so weit vom Trunk, dass die Reintegration häufig ein großes Abenteuer ist.
Trunk basierte Entwicklung
Aber wir hatten ja einen Heilsbringer in Form eines agile Coaches. Der sagte, dass Story Branches gar nicht agil sind und man im Sinne von Continuous Delivery doch lieber auf trunk-basierte Entwicklung umstellen soll. Wenn eine Story nicht fertig wird, ist das für uns ja auch kein Problem, denn es wurde noch nie eine Story verworfen. Sie muss eh vollständig implementiert werden. Wenn sie nicht in diesem Sprint fertig wird, dann wird sie im nächsten Sprint auf jeden Fall weiterentwickelt. Also verordnet er dieses Experiment. Es ist also nicht unbedingt so, dass die Teams dem Mann mit der Sandale freiwillig gefolgt wären.
Es ist ja nicht so, dass die Literatur nicht voll ist mit Ratschlägen zu dieser Art der Entwicklung. “(Mainline development) is an extremely effective way of developing, and the only one which enables you to perform continuous integration.”, sagen schon Jez Humble und David Farley in ihrem Buch “Continuous Delivery”. Schafften wir es jetzt endlich unsere PS auf die Straße zu bekommen? Leider nein. Aber solche Autoren können sich doch nicht irren, oder? Was machen wir falsch, warum standen Buchstäblich im Jenkins alle Ampeln auf rot? Ach ja, wir haben uns nicht ganz an den Prozess gehalten. Im Continuous Delivery Buch steht nämlich auch noch gleich ein einfacher Prozess geschildert:
- […] wait for it to finish […] work with the rest of the team to make it green before you check in
- …
- Run the build script and tests on your development machine […]
- […]
- Wait for your CI tool to run the build with your changes
- […]
- If the build passes, rejoice and move on to your next task
Und weiter heißt es: “If everybody on the team follows these simple steps every time they commit any change, you will know that your software works on any box with the same configuration as the CI box at all times.”
Da frage ich mich: Habe ich gerade richtig gelesen? Ich soll vor jedem Push alle Tests durchlaufen lassen und 30 Minuten oder mehr warten, dass alle noch grün sind? Ich meine: Das CI/CD System soll für mich arbeiten und nicht umgekehrt. Hat noch niemand was von der Cloud gehört? Außerdem will ich meine Arbeit sichern, d.h. einchecken können, wann ich will. Das bedeutet aber auch, dass ich meinen Build kaputt gehen lassen kann, wann ich will. Wir wollen Fehler ja so früh erkennen wie möglich. Breaking the Build is not a crime. Wenn das aber im Prozess der Trunk-basierten Entwicklung so ist, sollten wir vielleicht einmal das Prinzip der Trunk basierten Entwicklung hinterfragen. Was stimmt also nicht mit dem oben dargestellten Prozess der trunk-basierten Entwicklung?
Nachdem wir gerade so über diesen Prozess hergezogen sind, überrascht vielleicht die Erkenntnis: An der Idee der Trunk-basierten Entwicklung ist nichts falsch. Jetzt kommt aber das dicke ABER: Wir glauben, dass die meisten Entwickler, Coaches, Berater nicht verstehen, was damit gemeint ist.
Paul Hammant befasst sich in seinem Blog in mehreren Posts mit der Trunk basierten Entwicklung (TBD). Er tätigt in einem seiner wesentlichen Artikel folgende Aussagen:
- […] TBD is where all developers […] commit to one shared branch under source-control.
- Developers do not break the build with any commit.
Also leider keine neuen Erkenntnisse? Doch, nur leider hören hier viele auf zu lesen. Er schreibt auch:
- More sophisticated companies will use pre-commit verifications.
- Devs take on habit: prove the commit is good, by synchronizing to the the trunk’s latest revisions, building from root/scratch, double-checking their functional change, then committing.
Paul Hammant sagt also erst mal auch nur, dass es einen Dreiklang aus
- Rebase
- Build/Test
- Commit
Geben soll. Ok, auch nichts neues, deckt sich mit den Aussagen oben, oder? Vielleicht sollte man hier nicht aufhören zu denken, sondern fragen: Was schreibt er nicht im Blog? Er schreibt nämlich nicht, dass dies auf dem eigenen Rechner erfolgen muss. Er sagt, bevor man in den Trunk commitet, soll gezeigt werden, dass der Code “gut” ist.
Paul Hammant beschreibt auch nochmal Googles Workflow:
- One single repo
- Mondrian / Gerrit
- Extensive Tooling
Und dieses Vorgehen bedeutet, dass bevor etwas auf den Trunk commitet wird, ein Code Review mittels eines Reviewtools stattfindet. So ein Review Tool hat in der Regel auch folgende Funktionalität eingebaut:
- Rebase
- Build / Test
Um zu zeigen, dass der Code sich sauber integrieren lässt und mindestens eine gewisse Menge an Tests erfüllt. Daneben erfolgen mit diesen Tools pre-commit Reviews.
Was bedeutet das aber jetzt für unser Projekt? Die Ausgangssituation stellt sich zu diesem Zeitpunkt wie folgt dar: Wir betreiben TBD wie anfänglich beschrieben. Allerdings: Keiner lässt lokal alle Tests durchlaufen, das dauert viel zu lange. So viele Kaffeepausen kann man gar nicht machen. Und das hat zur Folge:
- Unser Trunk Build kennt meistens nur die Farbe Rot
- Meistens schlagen die E2E Tests fehl (deren Ausführung dauert auch am längsten)
- Fehlschläge haben wir in allen Teams
- Umbauten in der GUI, aber auch im Backend sorgen dafür, dass zum Teil mehrere Tage der Build fehlschlägt
- Als Lösung nutzen Teams Branches, allerdings ohne jegliche CI Unterstützung
Dies ist ein guter Zeitpunkt uns nochmal alle Anforderungen anzuschauen, die wir an einen CI Prozess haben:
- Bei Abhängigkeiten zwischen den Teams müssen auch Zwischenstände einer Story für andere Teams verfügbar sein
- Fehler in den Builds bzw. Behebung der Fehler sollen möglichst schnell sichtbar sein
- Im Regelfall sollte das System als Ganzes funktionieren und auf Test deploybar sein
- Fehlgeschlagene Builds sollten mit Commits im Zusammenhang stehen
- Größere Änderungen dürfen nicht dazu führen, dass andere Ergebnisse nicht ausgeliefert werden können.
- Bei bestimmten Arten von Stories sollten keine Zwischenergebnisse deployed werden, sondern erst der fertige Stand.
- Umfangreiche Merges sind zeitaufwändig und zu vermeiden (Regelmäßige, kleine Merges sind in der Regel kein Problem)
- Auch halbfertiger Code soll eingecheckt werden können, z.B. am Feierabend oder um mit Kollegen an einem Problem zu arbeiten.
Pre-Tested Commit Workflow
Die Lösung, für die wir uns entschieden haben und die vom Jenkins unterstützt wird, sind Pre-Tested-Commits.
- Entwickler commiten nicht direkt auf den trunk
- Sondern auf einem Branch (XXX/for/trunk) (KAW: Wonach werden diese geschnitten? User? Story?)
- CD System führt für jeden Commit eine Pipeline aus
- Workflow: Rebase, Tests, Merge in Trunk
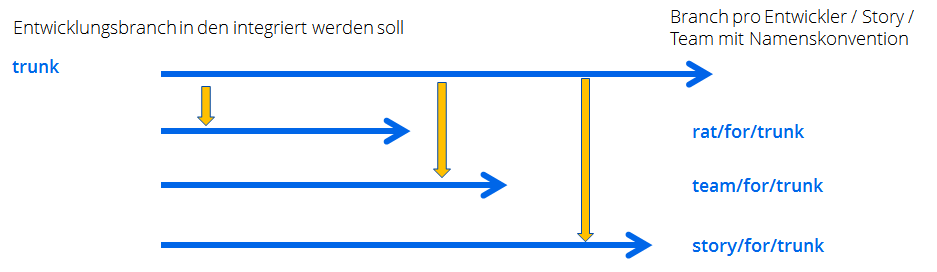 Branches können je nach Bedarf angelegt werden. Was sich etabliert haben sind Story- und Teambranches.
Der Teambranch übernimmt dann die Funktion des Masters für das Team. Allerdings ist nur das einzelnen Team davon betroffen,
wenn dieser nicht sauber baut.
Branches können je nach Bedarf angelegt werden. Was sich etabliert haben sind Story- und Teambranches.
Der Teambranch übernimmt dann die Funktion des Masters für das Team. Allerdings ist nur das einzelnen Team davon betroffen,
wenn dieser nicht sauber baut.
Auch wenn dies der Standard ist, erlauben wir weiterhin, dass jeder Entwickler auch direkt in den Trunk committet. Dies ist hilfreich, um schnell Änderungen an alle Teams / Branches zu verteilen oder um den Trunk schnell wieder “grün” zu bekommen, also Fehler auf dem Trunk zu beheben. Dabei gilt aber: Man sollte wissen was man tut oder mit dem Zorn der Kollegen leben.
Schauen wir uns die Pre-Pipeline etwas genauer an.
Rebase
Realisiert ist dies so, dass der Rebase über einen gitlab web hook ausgelöst wird. Geskriptet, passiert dabei ein Rebase. Je nach Ergebnis gibt es dann verschiedene Möglichkeiten:
- Rebase nicht erfolgreich: Build wird mit einer Fehlermeldung abgebrochen
- Rebase erfolgreich, es wurden Änderungen vom Master in den Branch gemerged: Pushe die Änderungen ans gitlab und starte nicht den Pre-Commit Flow
- Rebase erfolgreich, es gab keine zu mergenden Änderungen: Starte den Pre-Commit-Flow mit der Commit-Id
Der zweite Schritt startet keine Pipeline, da durch den Push der Codeänderungen der Gitlab Webhook wieder triggerd und dann 2 Pipelines mit den gleichen Änderungen ausgelöst würden.
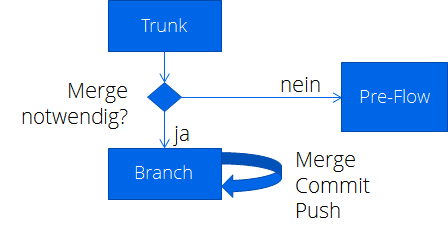
Pre-Flow
Mittels eines Config Files, welches mit dem Source Code versioniert wird und den Namen des Branches trägt, können verschiedene Aspekte des Pre-Flows konfiguriert werden. Ein wichtiger Aspekt ist es die auszuführenden E2E Testsuiten zu konfigurieren. Man kann dafür sorgen, dass im Pre-Flow nur ein Teil der Testsuiten läuft. Dies ermöglicht es Ressourcenbedarf, Feedbackzeiten und höheres Risiko (das der Trunk Build fehlschlägt) gegeneinander abzuwägen. Im Trunk laufen aber immer alle Tests. Diese Konfigurationsdateien bleiben auch nach dem Merge bestehen und müssen manuell gelöscht werden. Man könnte natürlich auch das automatisieren, allerdings sahen wir bisher dafür keinen Bedarf.
Generell gilt: Der Trunk-Build darf rot werten (selten), aber er sollte es nicht regelmäßig sein. Rot ist eine Farbe, die dem Trunk nicht gut steht, dem Pre-Flow aber durchaus.
Erkenntnisse
Was sind nun unsere Erkenntnisse aus der Reise
- Story Branches, die nicht regelmäßig gerebased werden, führen zu großen Problemen.
- Arbeiten direkt auf dem Trunk ist schwierig und nicht die Lösung unserer Probleme
- Naives TBD erfüllt nicht unsere Anforderungen
- Feature-Toggles, Branching-by-Abstraction und andere TBD Patterns brauchen wir aktuell nicht und würden aktuell zu höhrer Komplexität ohne höherem Nutzen füHerausforderungen
- Pre-Tested Commits unterstützen erfüllen für die Neuentwicklung unsere Anforderungen am besten
- Branches werden transparent unterstützt: Keine zusätzlichen Jobs im Jenkins notwendig
- Branches entfernen sich nicht weit vom Trunk
- Merge in den Trunk automatisch möglich
- Trunk bleibt grün
Unsere Erfahrungen mit den Pre-Tested Commits kurz zusammengefasst
- Jeder Push triggert einen Build: Dies bedeutet, wir haben einen erhöhten Ressourcenbedarf aber auch eine Zuordnung Fehler zu Push
- Gegen Sprintende sollte der Master Flow gegenüber Branch Flows priorisiert werden: Es laufen besonders viele Pre-Flows mit denen der Master um Ressourcen konkurriert.
- Cloudansatz für Infrastruktur wäre sinnvoll. Entwicklung in Sprints führt dazu, dass vor Sprintende mehr gepushed wird.
Und die wichtigste Erkenntnis: Kenne deine Anforderungen und entscheide dann über den Workflow.
Referenzen
- Advanced Continuous Integration, gearconf 2013
- Advanced Continuous Integration in der Praxis, Javaspektrum, 5/2014
- Zeig mir deinen Code, Jaxenter, Oktober 2014